Issue and Pull Request Conventions (part 2/3)
My previous post on GIT Conventions broke down various conventions around branching and committing code. As part of building a solid process around development, the next area to deal with is that of getting those branches and commits together for a merge and release. This is usually done via some sort of ticket on an issue tracker and code pull request. The following guide was developed as a collaborative effort with my team and lead to a more robust and progressive environment with improved communication and overall general happiness, even though it adds a little extra overhead.
Disclaimer: This is an evolving document which has been altered and tuned over the years. It may not apply to you and your situation but perhaps there is a nugget or two here that could improve your workflow and developer happiness.
Development Documentation
When it comes to software development in general, documention about the work being performed is incredibly important. Not only for your own understanding but for that of your team (and future you/team). Developers are lazy; documentation is a chore and it just slows us down; we want to code and deploy at the speed of light! The number of times I’ve had to go hunting through hundreds of previous PRs with incomprehensible titles and missing descriptions in order to find the correct one which holds the change that introduced a bug, is way too high and wastes and inordinate amount of my time and sanity.
A feature request or support ticket can come in from many different sources, perhaps a verbal suggestion from a product manager, or a ticket from a bug reporting system like Zendesk to JIRA. In order to unify these multiple sources into a single source of truth for the development team, the feature / issue would be written down into a Github Issue (we favoured Github as our central work hub, making use of their great tools), referencing the source when available.
Once the issue was drafted, it’s prioritisedd and assigned to a developer. The assignee would then spend a little time investigating the issue, collecting additional information, communicating with the various parties involved, and fleshing out the issue in a detailed and descriptive manner. With the issue in a good place, work can begin and once done, a PR created and linked to the issue. The PR didnt need to contain too much information, just a short description to help with searching for the most part, as the issue covers everything.
Issues
The central place for all information regarding a piece of work is the issue/ticket. We chose to use Github for our issues and pull requests however the structure defined here works with any project management tool. At the time, we had defined a ISSUE_TEMPLATE in our .github repository but that method is now deprecated in favour of the multi-issue type setup, however, each section still applies.
1. Description
The entrypoint and most important part of the issue. When developing a new feature, detail what the feature is, how it is intended to work, what problem will it solve and what was the reasoning behind this feature request in the first place. If the issue is a bug fix, detail what the bug is, how it was found and what was the cause of it, following with how you went about resolving it. This may sound like you need to write a thesis to explain the code change but all of this could easily be construed in a few concise sentences. It can take a little practice and if you’re struggling to form a short but clear, comprehensive description of the task at hand, perhaps ask ChatGPT to summarise it for you :P
2. Links
This section contains all links associated with the changes needed so that those inspecting the issue can quickly and easily navigate to all related material. This could be other PRs which are linked to the change (perhaps backend and frontend PRs are necessary), the support tickets that spurred on the change, documention or external resources (blog post, stackoverflow entry, etc) used in order to achieve the solution and whatever else could be of interest.
3. Integration Environment
At my previous employ, our CI/CD pipeline would deploy the PR to a newly spun up integration environment with seeded database in order for QA to have a running instance to test on. In the nature of providing all information in one place, this section included the URL to the CI/CD process responsible for creating (and destroying) the temporary environment, all associated web addresses to the various platforms and servers that might need accessing, as well as SSH instructions to the integration server in questions.
4. Testing Notes
This section allows you to define a structured and clear process for QA to test the changes you have made. Perhaps they are same as the reproduction steps cited in a bug report, or detail how to use a new piece of functionality. A step-by-step guide will help QA test your change but also identify where they could attempt to break it, ensuring you have put in place proper protection mechanisms such as validations or rescue conditions.
5.1 Migrations (Optional)
Database migrations can be a real headache if not done correctly. Sometimes a migration file will be added but the schema forgotten. Or the migration itself contains code to update a table with some new / altered values which falls apart on massive data sets. You may be able to correct mad migrations locally by just dropping and recreating the database, but you will have no such luck in production. Failed migrations can really throw a spanner in the works, therefore it is most important to make your team mates / QA / product aware that your work includes migrations and the team as a whole can battle test it (perhaps with a dry-run against a production replica database) and be on hand should anything go wrong.
5.2 Additional Notes (Optional)
Sometimes, there are other random tidbits you wish to include, perhaps direct messages to team members regarding anything written above, or notes to yourself reminding you to deal with something you stumbled upon when doing this work. This is where you can dump all those extra thoughts / notes / ideas / suggestions so that you can have it off your mind and have it available to remind your later.
Example
As I am unable to share actual issues from work (trade secrets and all that), I have put together a dummy example based on the information above. The description could be a bit more detailed, however, there was image size considerations to take.
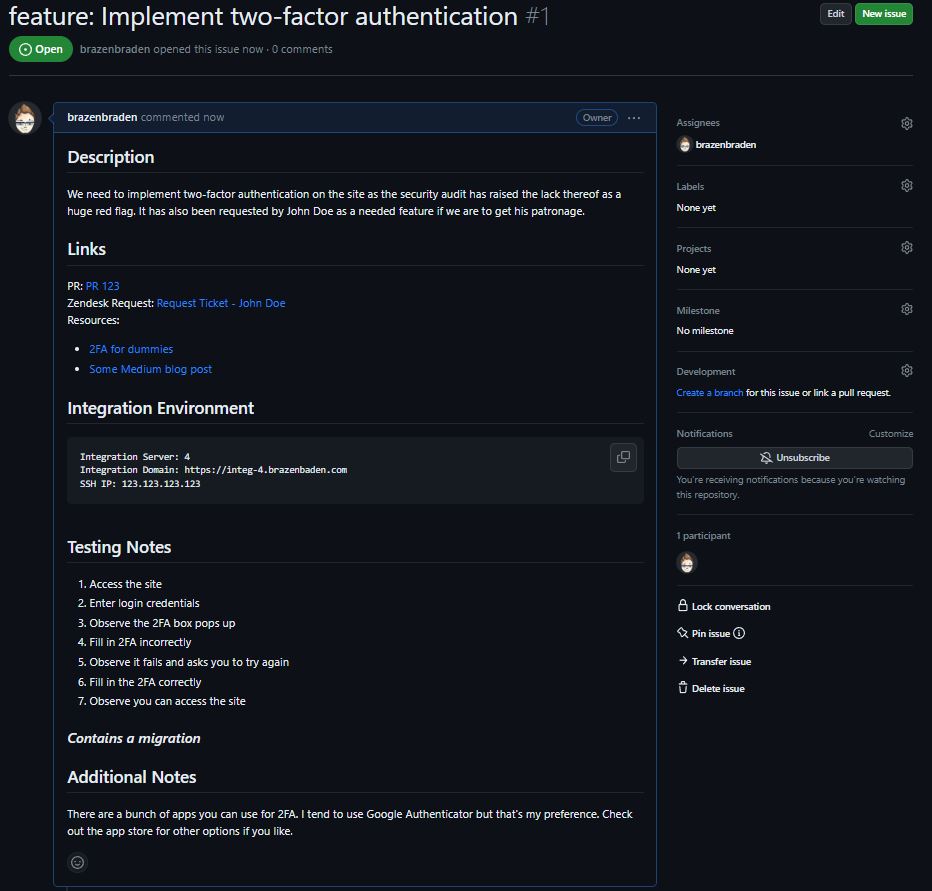
Pull Request (PR)
Given we provided all the information needed for the work done in the associated Issue, as well as ensuring all discussion is kept to the issue (comments), we keep the PR relatively simple.
- A basic summary of the work done (one or two sentences) was required, purely in order to assist searching for the PR in the future (an empty PR description gets lost forever).
- After the short summary, a link to the Issue is added. If you use Github projects, you can conveniently create links between PRs and Issues, more in their documentation here.
- The owner(s) be assigned to the PR.
- Link other relevant PRs to connect GitHub timelines
Next Up
As mentioned up at the top, by nature, developers are lazy. There could be push-back when attempting to introduce these conventions which is understandable but in time, the team will come to understand and appreciate the detail and extra depth provided around any piece of work, especially when it comes to bug hunting, refactoring or feature improvement. Being able to sit and clearly write down what you are doing, why you are doing and how you are doing also allows us to step back from the code and look at it from a wider perspective, which in turn could open our eyes to other possible solutions, questions, or problems which could arise from the planned work.
The next post (and final in this series) will focus on turning our completed work with detailed issue and associated PR, into a mergable unit which undergoes QA, merging and finally release!