Release Process (part 3/3)
After having followed the various conventions defined by our Git and GitHub processes, we should now be in a good place to take the code that has been produced, get it ready for QA, merge and release it. Every organisation will have their processes and workflows set around this, some good, some bad. I worked with my team to build a robust and practical release process which best suited our needs at the time, allowing for a quick development - QA - release lifecycle. We didn’t quite achieve the continuous-release dream, but we got close.
Disclaimer: This is an evolving document which has been altered and tuned over the years. It may not apply to you and your situation but perhaps there is a nugget or two here that could improve your workflow and developer happiness.
QA / Testing
As anyone will know, the QA process of manually testing and sanity-checking code changes in a piece of work can often take 10 times the duration it took to make the changes in the first place, depending on the size of the changes requiring testing. No one wants to hand over some work for QA, and have the QA engineer spend a day testing it, only to find a silly bug or edge case which could have been caught by a code review or proper test harness, resulting in the PR being handed back to the developer to make the fixes, resetting any QA progress. QA time is limited and not to be wasted. Therefore, we do as much as we can before handing over to QA, ensuring to the best of our ability, that they have a bug-free, fully functional code change to test, limiting pushback.
1. Green CircleCI workflow
We were in a good place with our test coverage, with a minimum of 98% coverage. Our testing suite was split up over a parallelised CircleCI workflow allowing for relatively fast builds and giving us the chance to ensure our entire test suite went green before moving on to requesting developer reviews. 95% of the time, our test harness would catch any accidental bugs or code smells, enabling us to pass clean, “bug-free” code to the team to review.
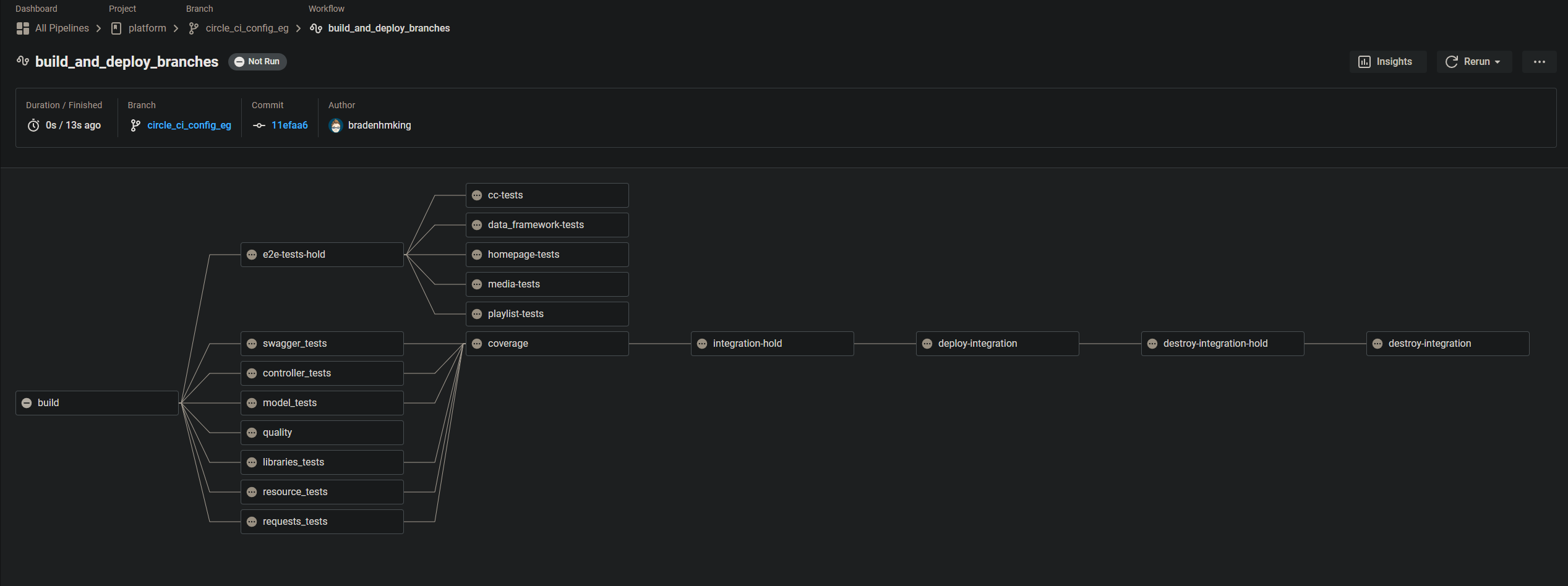
For this post, I didn’t bother waiting for the entire build process to go green before screenshotting, but you get the idea.*
2. Deploy to an integration environment
Thanks to our DevOps engineer, we had a flexible integration deployment system built right into CircleCI. On approval of integration deployment, a fresh new VM would be spun up, our code checked out, and all systems set up for manual testing. We would sanity check our changes on a “production” system because all too often, you hear the phrase “Well, it worked on my machine”. Subtle differences between development and production environments can result in a working dev build failing in production. This also gives us a chance to properly document how QA should go about testing our changes for when it gets handed over. For much larger features, we would use these environments for demos and to demonstrate the new functionality to the rest of the team, assisting with their code reviews.
3. Developer code reviews
Once we were confident all tests and code quality checks were passing, and we have sanity checked our own work, we would then request two developer reviews. This gave other developers the chance to familiaralize themselves with the changes, and ensure the code was clean and well written, fully tested and optimised. Oftentimes, a fresh set of eyes might identify an edge case that was missed or realise that a query is N+1 and could be optimised. Be there required code changes or not, after all is resolved and the team is happy, they would provide their two green ticks on the PR. We would also ensure our branch commits are in a good state by having done an interactive rebase against master, squashing and/or renaming commits to follow our conventions.
4. Hand over to QA
Once we are confident that our code works, we have the approval of the team and we are happy that our manual testing and sanity checks have all passed, the PR finally gets flagged for QA. QA will then test our code on the integration environment we used for our testing (creating their bespoke test data) and be guided by our specified testing steps and notes. A QA intends to break the code, so it is at this point all the weird and missed edge case testing usually happens and bugs are discovered, if present. Regardless, once QA has taken their sledgehammer to the work, and finds it without fault, they will provide their final green tick on the PR, leaving the PR with a total of 3 green ticks. We are now in a state to merge the work into master.
Merging
 Before we merge a branch to
Before we merge a branch to master, a couple of final steps are taken to ensure as smooth a process as possible.
1. Rebase and commit squashing
During the previous QA testing phase, there may have been various code changes required or bugs resolved. Before we commit to merging the branch after all the checks are green, we ensure our branch is up-to-date with the latest master by performing an interactive rebase against it, and squash any necessary commits, ensuring a clean, flat, and well-written git history is maintained (as per our Git Conventions). Ideally, there would have been no additional code modifications, so this step could be skipped as we do this before handing it over for dev review.
If there were merge conflicts that needed resolving, that means other work has made it in which may affect your code changes. In this instance, we would, based on the conflicts, possibly ask QA to go over the PR one more time before it gets merged, based off team decision.
2. Checking for migrations
Migrations can be tricky things. Testing a migration against a local database means nothing when run against a production database. Something as simple as changing a column name can bring an application to its knees if done incorrectly. Very often, one will see code-altering data in the database inside the migration (yes, this is a bad practice and shouldn’t happen in a perfect world, but this is not a perfect world) which, when operating on millions of rows in a production database, can cause database locks and timeouts, failing the deployment process. Having been bitten too many times in the past by dodgy migrations requiring a release rollback, we opted to isolate any PRs that contained any database migration changes and deploy them as standalone. It is at this point that QA would flag the PR for isolated deployment to, in the worst case of a rollback, not have other PRs affected by the rollback.
3. Merging into master
Our master branch was protected against merging by everyone except our lead QA engineer, the most senior dev and the CTO. In 99.9% of instances, merging was done by our QA engineer, allowing for a controlled merge process. This also prevented untested code from sneaking into master under the guise of a “hotfix” or other such shenanigans.
Release
Our dream was to have rolling deploys - as soon as anything was merged into master, it would deploy. At the time of writing, however, we were working off manual releases, usually containing a handful of PRs.
Tag and generate release docs
GitHub made it easy to generate our release notes as it can do so automatically when creating a new release. Specify the new tag to be applied to master branch (major/minor/micro version bump), ask Github to generate the release notes and that’s it. Thanks to our strict use of git commit conventions, the release notes description was clear without needing additional modification most of the time. For larger, more involved features, additional context would be supplied to better communicate the changes with our users.
Migration-induced isolated deployment
If a PR containing a database migration is flagged, a release will be created containing all previous PRs that have been merged since the last release, excluding the migration PR, and that will be deployed. The PR containing the migration would then get merged and a new release would be created straight away with only this PR. This was to ensure that there are no potential issues from compound migrations and also to allow quick and simple rollback should there be an issue. All this was made easier by having the master branch locked down to lead QA merging only, meaning nothing else could slip from elsewhere.
Press the button
 Once the release tag has been created, the entire CircleCI build would run once more, running the entire test suite, including the slower integration test suite (not run by default) and once green, the release would be approved through CircleCI and off it goes. As we had a blue-green delivery process in place, a whole new cluster of pods would spin up with the new release, and only after all the various checks were completed ensuring all services were running without issue, we would have the load balancer switch over to the new pods and start killing off the old ones.
Once the release tag has been created, the entire CircleCI build would run once more, running the entire test suite, including the slower integration test suite (not run by default) and once green, the release would be approved through CircleCI and off it goes. As we had a blue-green delivery process in place, a whole new cluster of pods would spin up with the new release, and only after all the various checks were completed ensuring all services were running without issue, we would have the load balancer switch over to the new pods and start killing off the old ones.
That’s all folks
And that concludes part 3 of my documentation about the processes and workflows we built and fine-tuned over the years around the development lifecycle. It may not be perfect and there was a lot more we wanted to do (rolling deploys, etc) which we hadn’t quite gotten to, but what we did have in place worked well for us. Sometimes the smallest change at the beginning of the process can produce significant wins at the end of the process. For instance, how our release note documentation was generated descriptively and concisely based on our git commit conventions, or how our GitHub documentation process helped us find where bugs were created years later due to easy searching.
All of these processes took some time, effort and accountability to become habits. There would be moans and groans when a PR was rejected because the branch name didn’t match the pattern (look up Git move) or when an interactive rebase to squash that final “fix issue” commit tacked on during the review process was insisted upon, or blocking a PR until it had a decent enough description. Some might find these requests to be petty but looking back on the bubbling effect of them, the entire team would agree it was worth putting in that extra leg work at the end of the day.